In the world of Artificial Intelligence (AI), there’s a common saying: “Garbage in, garbage out.” This phrase underscores a key truth—the quality of the data used to train AI models directly impacts their accuracy and effectiveness. If the data is poor, the model will yield poor results, no matter how sophisticated the algorithms are.
High-quality data ensures that AI models can make accurate predictions, avoid biases, and operate efficiently. It is essential for any AI project’s success, from machine learning (ML) models predicting stock trends to healthcare applications diagnosing diseases. In this blog, we’ll dive into why data quality matters so much and how you can ensure your data is up to par.
Why Data Quality Matters in AI Models
1. Accurate Predictions and Insights
AI’s main goal is to generate accurate predictions based on data. When the data is full of errors or inconsistencies, the model will inevitably struggle to make correct predictions. For example, an image recognition AI trained with blurry or mislabeled images will have trouble identifying objects accurately. In healthcare, poor data could lead to misdiagnoses or incorrect treatment recommendations, which can have serious consequences.
High-quality data helps AI models recognize the correct patterns and provide reliable insights. The model can then generate results that mirror real-world conditions and improve decision-making.
2. Avoiding Bias and Fairness Issues
AI models learn from the data they are trained on. If that data is biased, the model will likely reflect those biases in its predictions. For example, a hiring algorithm trained on biased data might favor one demographic over others, resulting in discriminatory practices. Similarly, facial recognition systems might struggle to identify certain racial or gender groups if the training data lacks diversity.
To ensure fairness, it’s important to use a diverse and representative dataset. By doing so, AI models can produce decisions that are more equitable and free from bias.
3. Enhancing Model Efficiency
When data is clean, consistent, and well-structured, AI models train faster and perform better. Poor-quality data requires more time for cleaning, labeling, and preprocessing. This added workload not only slows down model development but also increases costs. Additionally, bad data can cause models to overfit or underfit, leading to poor generalization to new data.
Efficient models require minimal cleanup and are less prone to errors, meaning you can quickly deploy them with confidence.
4. Better Generalization to Real-World Scenarios
AI models must perform well in real-world scenarios, which are often unpredictable. For example, self-driving car AI must recognize and adapt to a wide variety of road conditions, weather, and unexpected obstacles. If the training data doesn’t reflect these diverse situations, the model might fail when it encounters something new.
By training with high-quality, varied data, AI models can better generalize to real-world applications. This helps ensure that the model performs well in different conditions and maintains its reliability.
What Constitutes High-Quality Data?
1. Relevance
The data used to train AI models must be relevant to the task at hand. For example, if you’re developing a model to classify animals, you need images of animals from various environments—not images of cars or buildings. Irrelevant data can confuse the model, leading to errors.
2. Accuracy
Data must be accurate. Mislabeled data or faulty measurements can mislead the model. For example, if an image recognition AI is trained with incorrectly labeled photos, it will learn the wrong associations and produce inaccurate predictions.
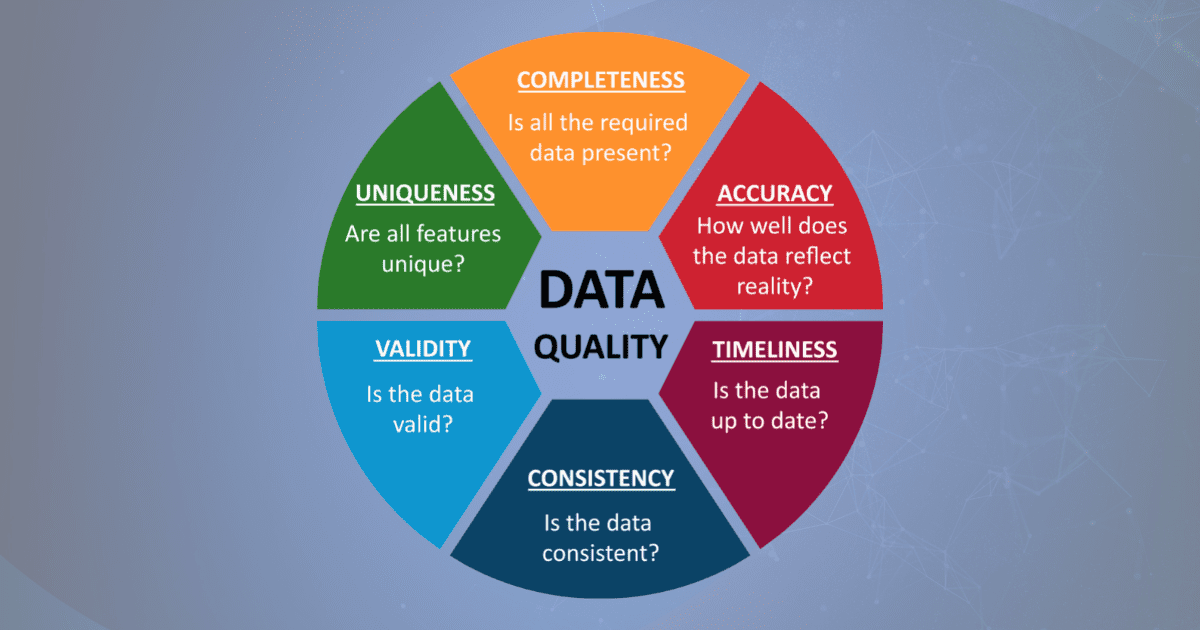
3. Completeness
Incomplete data poses a significant challenge. Missing data can leave gaps in the model’s understanding, which can hinder its performance. For example, a dataset used to predict customer behavior might miss important demographic information, leading to flawed predictions.
4. Consistency
Consistent data formats and structures are crucial for efficient training. If data comes in various formats or includes inconsistent values (e.g., different date formats), it will take extra effort to preprocess. Standardizing the data ensures that the model processes it correctly.
5. Diversity
A high-quality dataset must be diverse. AI models trained on homogeneous data may perform well for certain groups but fail when applied to others. For example, a facial recognition AI trained on data from a specific demographic may struggle with people from other ethnic groups. Ensuring diversity in the dataset improves fairness and the model’s ability to handle varied real-world inputs.
6. Volume
While data quality is more important than quantity, the volume of data still matters. Generally, the more diverse, relevant, and accurate data you have, the better your model will perform. However, more data isn’t always better if the quality is compromised.
How to Ensure High-Quality Data for AI Training
1. Data Collection and Curation
Gather data from reputable and relevant sources. Ensure that it is diverse, accurate, and reflective of the real-world conditions that your model will face. It’s also important to gather data that covers edge cases and rare scenarios.
2. Data Cleaning and Preprocessing
Clean the data by removing errors and inconsistencies. Preprocess it to ensure that it’s structured and formatted correctly for the AI model. For instance, you might need to normalize numerical data or encode categorical values for use in the model.
3. Data Labeling
In supervised learning, data labeling is crucial. Labels must be accurate and consistent. It’s important to involve domain experts for labeling to ensure high quality. Regular audits of labeled data help maintain quality as datasets evolve.
4. Monitoring and Auditing for Bias
Regularly check your dataset for biases. Biases in data can have a significant impact on model fairness. Addressing bias early in the training process helps the model make fairer predictions. There are also fairness-aware algorithms that can help identify and mitigate bias in data.
5. Data Augmentation
When data is scarce, consider using data augmentation techniques. This involves generating new data by applying transformations (such as rotations, flips, or noise) to existing data. This can help create a more diverse and comprehensive dataset for training.
Conclusion
The quality of the data used to train AI models directly impacts their performance, fairness, and accuracy. High-quality data allows AI systems to make accurate predictions, avoid biases, and generalize well to real-world scenarios. By ensuring that your data is relevant, accurate, complete, consistent, and diverse, you can build AI models that are more reliable and impactful.
When starting a new AI project, always remember: the foundation of your success lies in the quality of the data. Without good data, even the most advanced algorithms will fall short.


